Posted on August 17, 2023
In this post, I’ll explain what comonads are, how they relate to monads, and how they can be used to model the game logic of 2048. I will also present a simple program that demonstrates the comonadic approach to 2048, and go through the implementation step by step. Lastly, I’ll go over why you might choose comonads over other approaches, and what the pros and cons of each are.
I’ll give a brief overview of the mechanics of 2048 for those who are unfamiliar: 2048 is a game where you slide tiles around a 4x4 grid. Each tile has a value, and when two tiles with the same value collide they merge into a single tile with the sum of their values. The goal of the game is to get a tile with the value of 2048. The game ends when the grid is full and there are no more moves to make. If you’ve never played it, try it out here, just beware it can be very addictive.
What is a Comonad anyways?
Comonads are a concept from category theory, which is a branch of mathematics that studies abstract structures and their relationships. Category theory is also a useful tool for reasoning about programming, as it provides a common language to describe different types of computations and their properties.
If you’ve used Haskell for some amount of time you might have heard of monads. Monads are a way of composing functions that produce some extra effects or context, such as IO, state, or randomness. Monads can be seen as a generalization of the idea of chaining computations with the bind operator (>>=) in Haskell.
Comonads are the dual of monads, which means that they reverse the direction of the arrows and swap the roles of the components. Comonads are a way of composing functions that consume some extra context or environment, such as streams, arrays, or trees. Comonads can be seen as a generalization of the idea of applying functions with the extend (<<=) operator in Haskell.
To define a comonad in Haskell, we need three things:
- A type constructor
wthat is a functor, which means that it can map any functionf :: a -> bto a functionfmap f :: w a -> w b. - A function
extract :: w a -> athat can extract a value from anyw-context. - A function
extend :: (w a -> b) -> w a -> w bthat can apply any functionf :: w a -> bto anyw-context.
These three components have to satisfy some laws that ensure that they behave well together. The laws are:
extract . extend f = f
extend extract = id
extend f . extend g = extend (f . extend g)These laws are analogous to the monad laws, but with the arrows reversed.
How do comonads relate to monads?
Monads and comonads are both special cases of adjunctions, which are pairs of functors that have a natural correspondence between them. An adjunction consists of two functors f :: C -> D and g :: D -> C, and two natural transformations unit :: id -> g . f and counit :: f . g -> id, such that:
fmap counit . unit = id
counit . fmap unit = idAn adjunction gives rise to a monad on C by composing g . f :: C -> C, and defining:
return = unit
(>>=) = fmap counit . flip (.) unitSimilarly, an adjunction gives rise to a comonad on D by composing f . g :: D -> D, and defining:
extract = counit
extend = fmap unit . flip (.) counitIn fact, every monad arises from an adjunction in this way, and every comonad arises from an adjunction in the opposite way.
Comonads In Haskell
Now let’s try to make the comonad in Haskell! First we reverse the arrows of the monad. Here we can see our Monad class that we’re familiar with:
class Functor m => Monad m where
return :: a -> m a
join :: m (m a) -> m a
bind :: (a -> m b) -> m a -> m bHere’s what happens when we reverse them:
class Functor w => Comonad w where
extract :: w a -> a
duplicate :: w a -> w (w a)
extend :: (w a -> b) -> w a -> w bI’ve renamed each function to their standard names. extract is the dual of return, duplicate is the dual of join, and extend is the dual of bind. Comonads can have default implementations of extend and duplicate in terms of each other. Here’s what that looks like:
duplicate :: w a -> w (w a)
duplicate = extend id
extend :: (w a -> b) -> w a -> w b
extend f = fmap f . duplicateThis means when implementing an instance of Comonad, you only need to implement extract and extend or duplicate. Many common programming constructs, such as streams and zippers, can be considered as a Comonad. Here’s an example of a stream:
data Stream a = Stream a (Stream a)We can make this a Comonad by defining extract and extend:
instance Comonad Stream where
extract (Stream a _) = a
extend f s@(Stream _ t) = Stream (f s) (extend f t)Let’s use this stream to get a better understanding of how a comonad works. The extract function is pretty simple, it just returns the value of the current element much like head for a list. The extend function is a bit more complicated. It takes a function f :: Stream a -> b and a stream s :: Stream a, and returns a new stream Stream b. The first element of the new stream is the result of applying f to the original stream s. The rest of the elements are the result of applying f to the tail of the original stream t. This means that extend is a way of applying a function to a stream, and getting back a new stream of the results. This is similar to how map is a way of applying a function to a list, and getting back a new list of the results.
Using Comonads to Model 2048
Now that we have a basic understanding of what a comonad is, let’s use it to model the game logic of 2048. There are many approaches to modeling the grid of tiles in 2048. The most commonly used data structure is a 2d array, but maps are also a good choice. In the same way that the Stream comonad is similar to the list, the Store comonad is similar to the Map data structure. Here’s what it looks like:
data Store s a = Store (s -> a) sThe Store comonad contains a function from a key s to a value a, and a key s. We can make this a comonad by defining extract and duplicate:
instance Comonad (Store s) where
extract (Store f s) = f s
duplicate (Store f s) = Store (Store f) sFor our key datatype s, we’ll use a pair of integers (Int, Int). This will allow us to represent the coordinates of each tile in the grid. Our value datatype a will be an Int, which will allow us to represent the value of each tile. With that we can create a type for our grid and also include a datatype for the direction of a move:
data Direction = L | R | U | D deriving (Eq)
type Position = (Int, Int)
type Value = Int
type Grid a = Store Position aNow that we have a type for our grid, we can start implementing the game logic. Going back to what I said previously, comonads are perfect for computations that need a context. For implementing movement in 2048, we need to know the direction of the move, and the row / column of the tile. There is a handy helper function that will allow us to implement this cleanly:
experiment :: Functor f => (s -> f s) -> Store s a -> f a
experiment f (Store g s) = fmap g (f s)This function seems strange at first but I’ll demonstrate how it works. We can use experiment to retrieve all the tiles in the current tile’s row or column. Here’s what that looks like:
rowIndices :: Direction -> Position -> [Position]
rowIndices dir (x, y) =
case dir of
L -> [(x, y) | x <- [0..maxSize]]
R -> [(x, y) | x <- [maxSize, maxSize - 1..0]]
D -> [(x, y) | y <- [0..maxSize]]
U -> [(x, y) | y <- [maxSize, maxSize - 1..0]]
toRow :: Direction -> Grid a -> [a]
toRow dir = experiment (rowIndices dir)Now we have to implement the movement and merging logic. We can use toRow to get the row or column of the current tile, and then use moveRow to move the tiles in that row. Here’s what that looks like:
moveRow :: [Value] -> [Value]
moveRow x = let x' = moveRow' (filter (/= 0) x)
in x' ++ replicate (length x - length x') 0
where moveRow' [] = []
moveRow' [x] = [x]
moveRow' (x:y:xs)
| x == y = x + y : moveRow' xs
| otherwise = x : moveRow' (y:xs)
gameRule :: Direction -> Grid Value -> Value
gameRule dir (Store f s) =
case dir of
L -> moveRow (toRow dir g) !! x
R -> reverse (moveRow (toRow dir g)) !! x
D -> moveRow (toRow dir g) !! y
U -> reverse (moveRow (toRow dir g)) !! y
where (x, y) = s
g = Store f smoveRow implements the movement and merging of the tiles in a row. gameRule uses toRow to get the row or column of the current tile, and then uses moveRow to move the tiles in that row. The !! operator is used to get the value of the tile at the current position. gameRule is a function that takes a direction and a grid, and returns the value of the tile at the current position after the move. Notice the type signature of gameRule you’ll see that if we partially apply it to a direction, we get a function perfect for extend.
The other game mechanic is the spawning of the game tiles after each move. We can use a simple if statement to implement that. The initial value of a new tile is always 2, but in the real game there is a chance for the tile to be 4 as well. For the sake of simplicity I am avoiding randomness. Here’s what that looks like:
addNewTile :: Grid Value -> Grid Value
addNewTile (Store f s) = Store (\x -> if x == (t !! (totalScore g `mod` length t) ) then 2 else f x) s
where t = emptyTiles g
g = Store f sTo choose the position of the new tile we use the total score of the grid. This allows a random looking distribution of the new tiles, while still being deterministic. The remaining game mechanisms aren’t particularly interesting to talk about, and don’t require comonads to implement. Here are their implementations:
totalScore :: Grid Value -> Int
totalScore (Store f s) = sum [f (x, y) | x <- [0..maxSize], y <- [0..maxSize]]
isWon :: Grid Value -> Bool
isWon (Store f s) = 2048 `elem` ([f (x, y) | x <- [0..maxSize], y <- [0..maxSize]])
isLost :: Grid Value -> Bool
isLost (Store f s) = null (emptyTiles (Store f s))
emptyTiles :: Grid Value -> [Position]
emptyTiles (Store f s) = filter (\x -> f x == 0) [(x, y) | x <- [0..maxSize], y <- [0..maxSize]]We also need to implement the initial state of the board. We create a new Store with the function \x -> 0 and the position (0, 0). This will create a grid of all zeros. We can use addNewTile to populate the board with the initial 2 tiles. Here’s what that looks like:
initialState :: Grid Value
initialState = addNewTile $ addNewTile $ Store (const 0) (0, 0)The last major thing we need to implement is displaying the grid. We could use experiment, but that would return a 1d list, which is more annoying to display. Instead, we can just use a 2d list comprehension to get the values of all the tiles in the grid. Here’s what that looks like:
render :: Grid Value -> String
render g = unlines $ map (unwords . map show) $ toLists g
where toLists (Store f s) = reverse [[f (x, y) | x <- [0..maxSize]] | y <- [0..maxSize]]Now we just need to handle IO and we’re done! We can use getLine to get the direction of the move from the user, and then use extend and gameRule to get the next state. We can then use addNewTile to add a new tile to the grid, and then use render to display the grid. Here’s what that looks like:
endCondition :: Grid Value -> IO Bool
endCondition g
| isWon g = do
putStrLn "You won!"
return True
| isLost g = do
putStrLn "You lost!"
return True
| otherwise = return False
mainLoop :: Grid Value -> IO ()
mainLoop g = do
putStrLn (render g)
end <- endCondition g
if end
then return ()
else do
putStrLn "Enter a direction (l, r, u, d): "
dir <- getLine
case dir of
"l" -> mainLoop (addNewTile $ extend (gameRule L) g)
"r" -> mainLoop (addNewTile $ extend (gameRule R) g)
"u" -> mainLoop (addNewTile $ extend (gameRule U) g)
"d" -> mainLoop (addNewTile $ extend (gameRule D) g)
_ -> mainLoop g
main :: IO ()
main = mainLoop initialStateIf you take everything we have done up to now and try to run it you’ll encounter an issue very quickly. The game becomes prohibitively slow after just a few turns. This is because we are using the Store monad without any memoization. This means that every time we calculate the next state we are recalculating the previous states for each tile. That’s obviously not ideal. We can fix in a number of ways but the easiest is to use the data-memocombinators package. I took this approach from Edward Kmett in his comonad tutorial. Here’s what that looks like:
import Data.MemoCombinators as Memo
tab :: Memo s -> Store s a -> Store s a
tab f (Store g s) = Store (f g) s
mainLoop :: Grid Value -> IO ()
mainLoop g = do
print g
putStrLn (render g)
end <- endCondition g
if end
then return ()
else do
putStrLn "Enter a direction (l, r, u, d): "
dir <- getLine
case dir of
"l" -> mainLoop (addNewTile $ extend (gameRule L . tab (Memo.pair Memo.integral Memo.integral)) g)
"r" -> mainLoop (addNewTile $ extend (gameRule R . tab (Memo.pair Memo.integral Memo.integral)) g)
"u" -> mainLoop (addNewTile $ extend (gameRule U . tab (Memo.pair Memo.integral Memo.integral)) g)
"d" -> mainLoop (addNewTile $ extend (gameRule D . tab (Memo.pair Memo.integral Memo.integral)) g)
_ -> mainLoop gNow that the memoization is in place, you can play 2048 to your heart’s content! You can find the full source code and GitHub project here. Here’s a gif of the game in action:
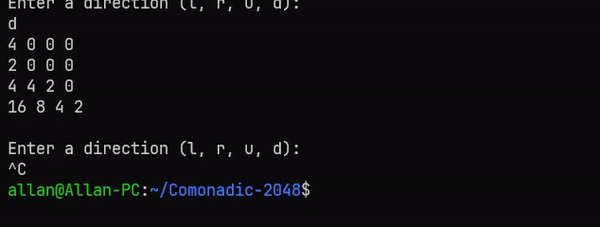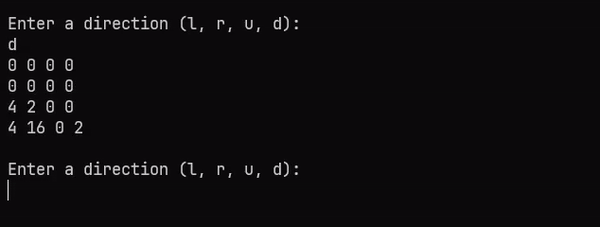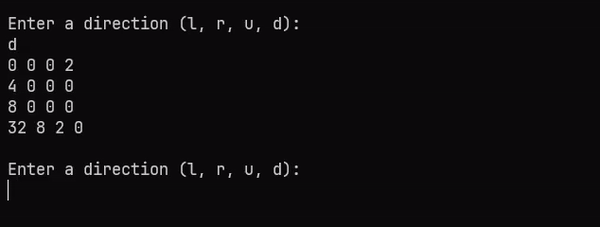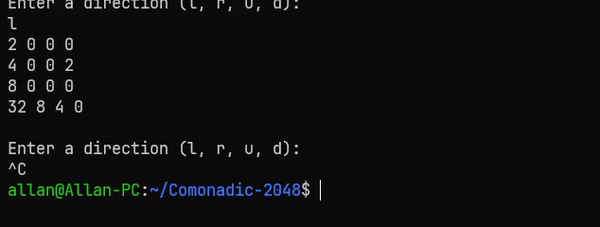
Why use Comonads?
Now that we have a working implementation of 2048 using comonads, let’s talk about why you might want to use comonads over other approaches. The main advantage for the our implementation is the elegance of the solution. The comonadic approach is very declarative and the main game logic can be expressed in just a few lines of code. Compared to working directly with a 2d list, like in this implementation (no shade to the author, by the way), the vast majority of the code is focused on implementing game logic, whereas our game logic is implemented in only a few functions, and half of the code is simply boilerplate for the comonad. If we used a library that implements a comonad for us, our game would be less than 50 lines of code. The style of the code is a personal but important factor and by using comonads we can write declarative code. Additionally, adding new game mechanics is very easy, since you can trivially compose functions of the form Comonad w => w a -> b. Other advantages that we didn’t see in our example are that comonads can be used to model many other things, such as streams, zippers, lenses, and cellular automata, and by writing code that is generic over comonads you can reuse it for all of these different things, which allows us to experiment with different data structures easily and compare performance. Lastly and most importantly, there is the flex of being able to say that you used comonads, and with that you can take one more step towards Haskell enlightenment.
However, it’s not all sunshine and rainbows. The path to enlightenment is a lonely one. Most programmers don’t know what a comonad is, and even fewer know how to use one. This means that if you use comonads in your code, you will have to explain what they are and how they work to your peers. This also means that if you need help, chances are, you’ll have to figure it out yourself. Compare that to the number of monad tutorials. Since comonads are niche, most libraries and tools don’t have support for them. Therefore, it’s likely that you’ll have to write a lot of boilerplate code just to get things working. Lastly, as we saw with our implementation, comonads can be prohibitively slow if implemented naively, which adds yet another layer of complexity.
Ultimately, these trade-offs are up to you to decide. But it’s always better to have something and not need it. So I encourage you to try using comonads in your next project, and see if they work for you.